记一次线上服务OOM的排查记录
现象
线上服务连续抛出三次java.lang.OutOfMemoryError: Java heap space异常后,直接抛出java.lang.OutOfMemoryError: GC overhead limit exceeded,后面数据库直接连接不上了,只要涉及到数据库的操作都在抛Failed to obtain JDBC Connection;
分析
Java heap space 这个容易理解,简单说就是堆内存不足了。
GC overhead limit 这个错误表示执行垃圾收集的时间比例太大, 有效的运算量太小. 默认情况下, 如果GC花费的时间超过 98%, 并且GC回收的内存少于 2%, JVM就会抛出这个错误。
每个Java程序都只能使用一定量的内存, 这种限制是由JVM的启动参数决定的。而更复杂的情况在于, Java程序的内存分为两部分: 堆内存(Heap space)和 永久代(Permanent Generation, 简称 Permgen):
这两个区域的最大内存大小, 由JVM启动参数
-Xmx和-XX:MaxPermSize指定. 如果没有明确指定, 则根据平台类型(OS版本+ JVM版本)和物理内存的大小来确定。
java.lang.OutOfMemoryError: GC overhead limit exceeded 错误只在连续多次 GC 都只回收了不到2%的极端情况下才会抛出。假如不抛出 GC overhead limit 错误会发生什么情况呢? 那就是GC清理的这么点内存很快会再次填满, 迫使GC再次执行. 这样就形成恶性循环, CPU使用率一直是100%, 而GC却没有任何成果. 系统用户就会看到系统卡死 - 以前只需要几毫秒的操作, 现在需要好几分钟才能完成。

dump内存
线上的服务不能一直拖,首先保证能用,但我还需要去排查这个问题的原因,所以直接dump内存,再重启服务
jmap -dump:format=b,file=heap.dump `pid of java`分析堆内存
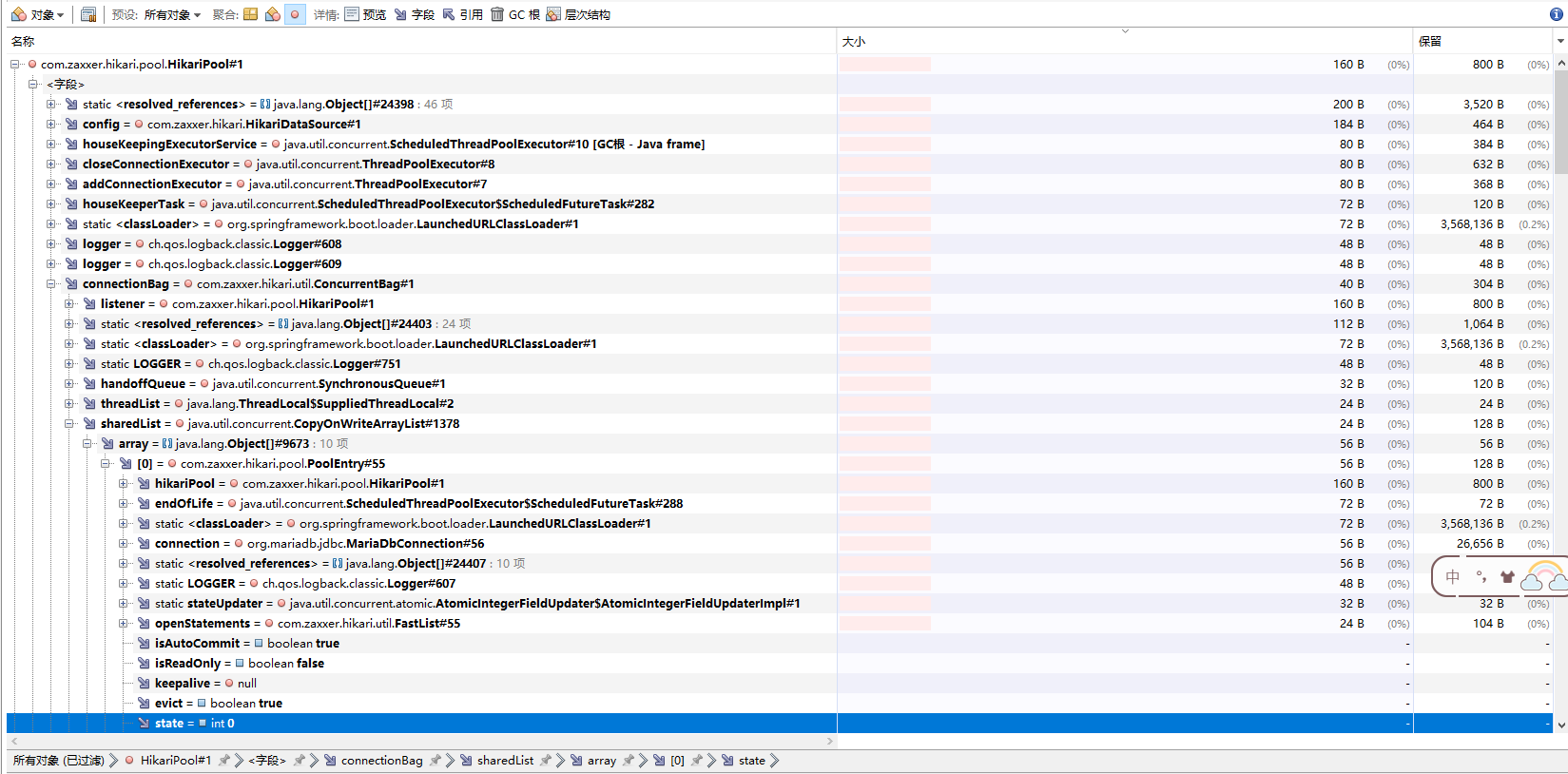
直接导入到VisualVM中,我倒要看看是哪个玩意儿这么大能撑爆:
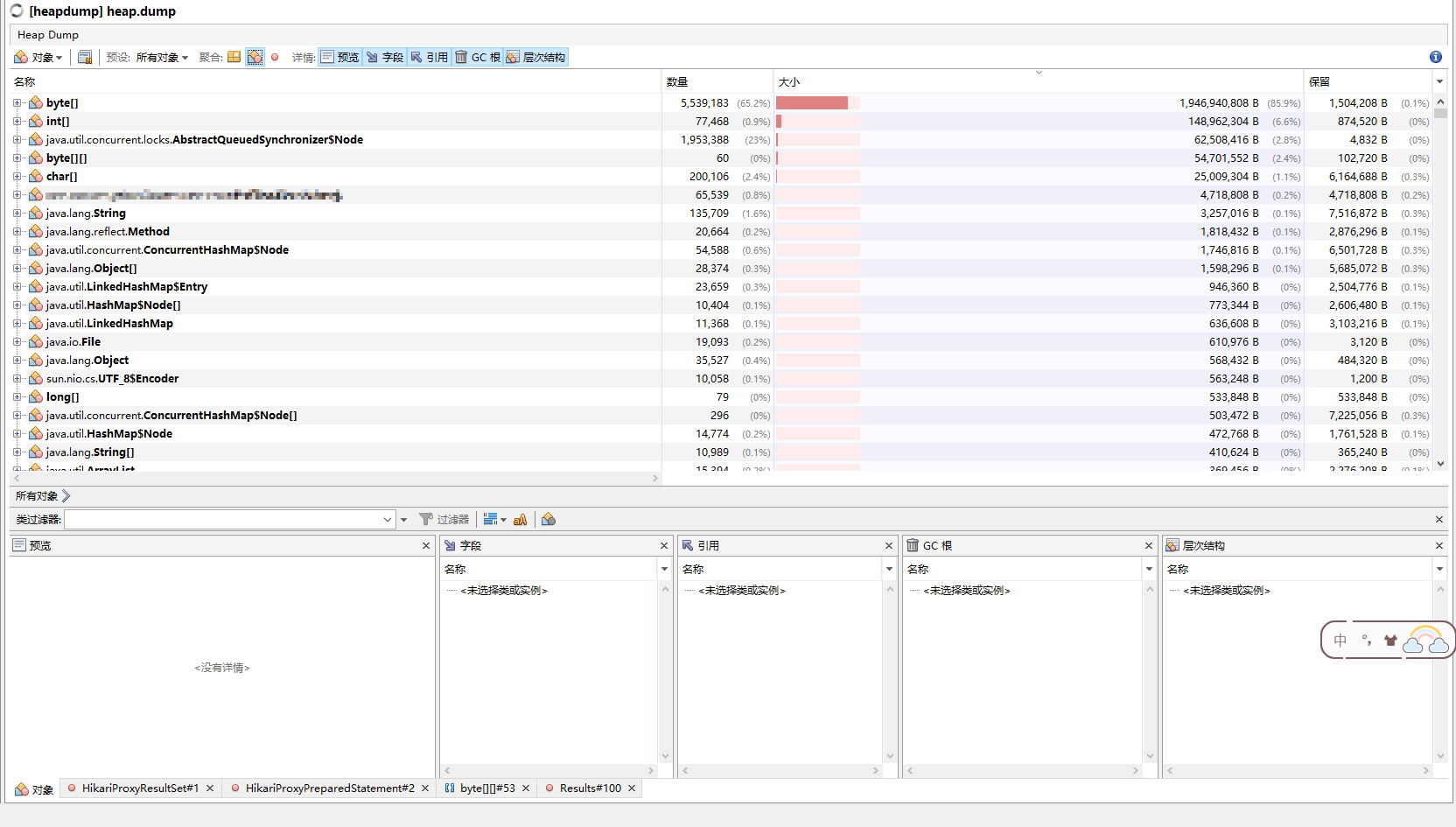
乖乖诶,byte[]类能这么大?第一反应是不是哪里泄露了,关键是这个服务也不复杂啊,基本都是增删改查,离谱哦~~心想是不是有什么占用大的Object,于是乎就看到这些个玩意儿:
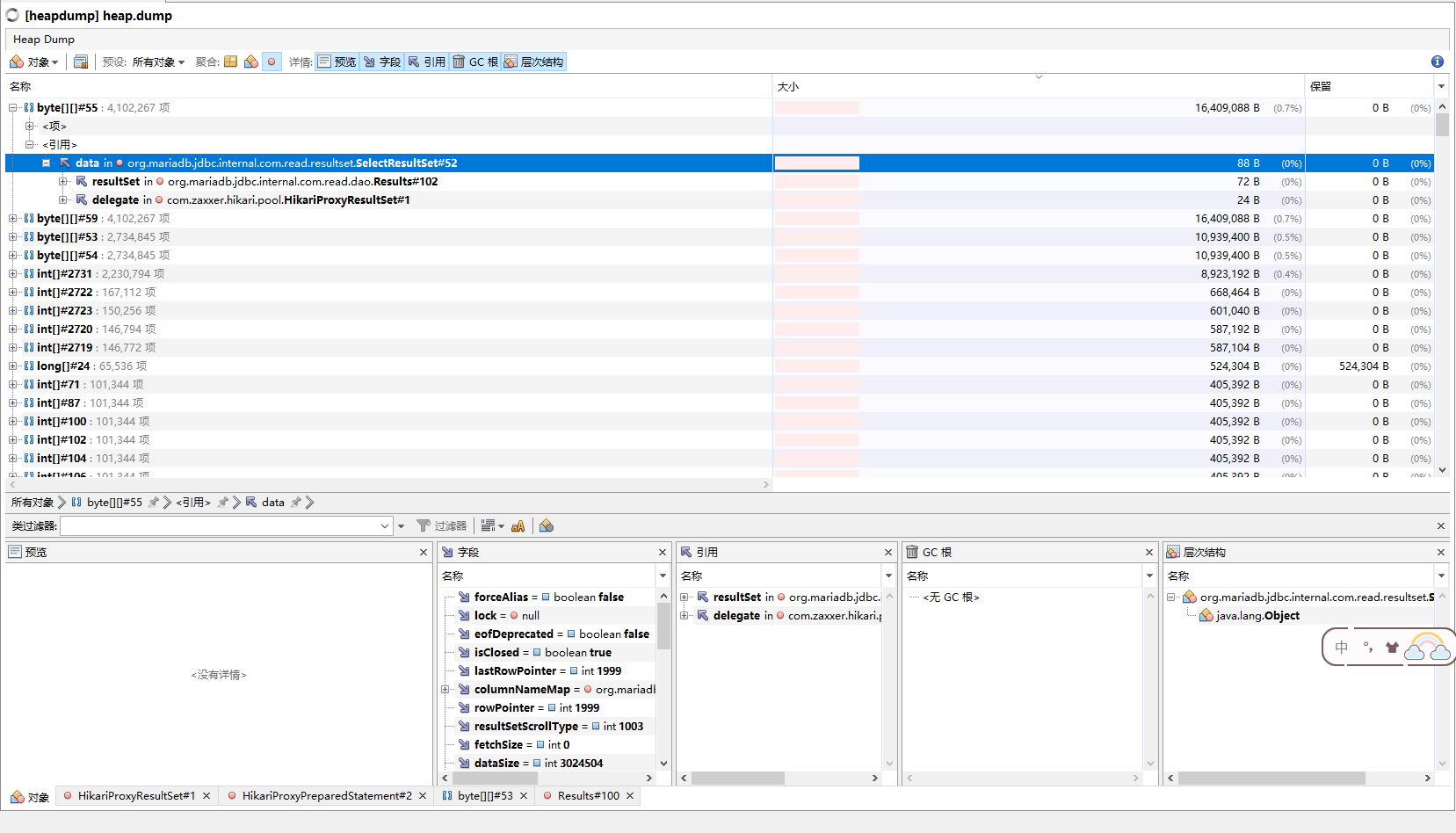
resultSet,这不是JDBC结果集的那堆东西么,这咋能这么大,接着往下找吧,看看都有些啥:
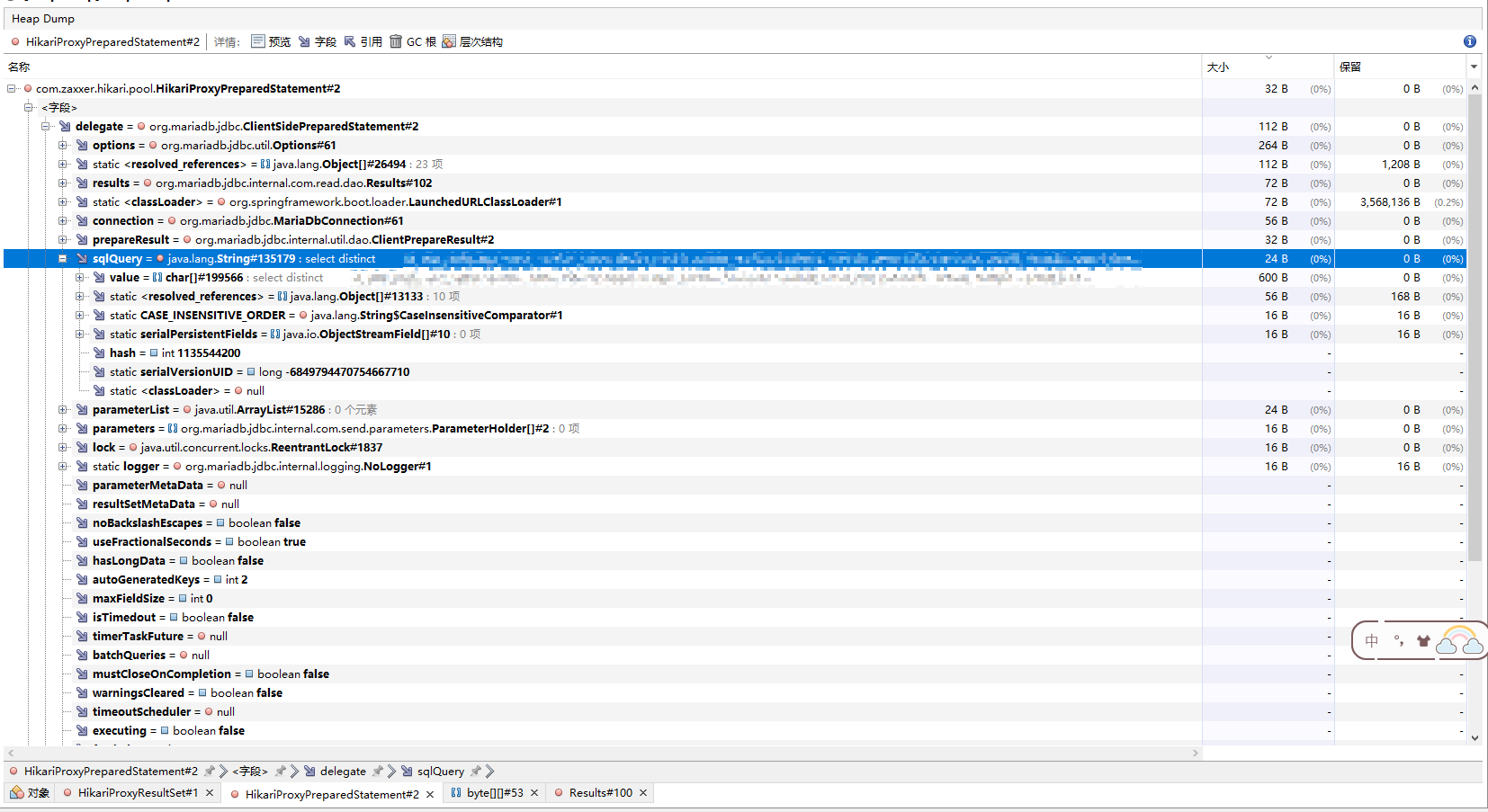
最后找到这么一条SQL,我翻了翻代码,这条SQL本应该是一个分页查询,但是最终的实际效果却是,把所有的结果都查出来,都给塞内存里,再取出相应条数的记录,关键是这条SQL能从表里查出来三四百万条记录,如果在两次GC之间进行多次查询,每次查个三四百万条记录放内存,内存多大也遭不住啊,我测试了下,每次分页查询,byte[]的内存占用肉眼可见的增长...
解决
解决方式也简单,直接更新下mybatis-plus,加上分页插件,优化下查询代码,效果就是在sql后面加上了limit offset,一次取相应的条数,而不是查所有记录。
另外还是有点问题没有搞明白,在OOM之后的所有数据库操作都会抛连接超时,怀疑是跟OOM有关,但是我又没找到直接原因,我又看了下HikariPool这个对象状态,也有可用连接啊,为什么就是连接超时呢?奇怪啊,正常来说Hikari应该维护连接池保证连接可用的,介是为嘛?还得继续深入学习哇~~~