







关于一次数据库Socket阻塞问题的记录
问题描述:
线上的一个服务偶发阻塞,查看日志发现当服务阻塞两小时之后还会自动恢复。
问题分析:
导出内存
线上服务阻塞时,dump服务内存快照,临时手动恢复服务运行。
jmap -dump:format=b,file=heap.dump `pid of java`分析内存
使用jvisualvm打开并分析内存快照
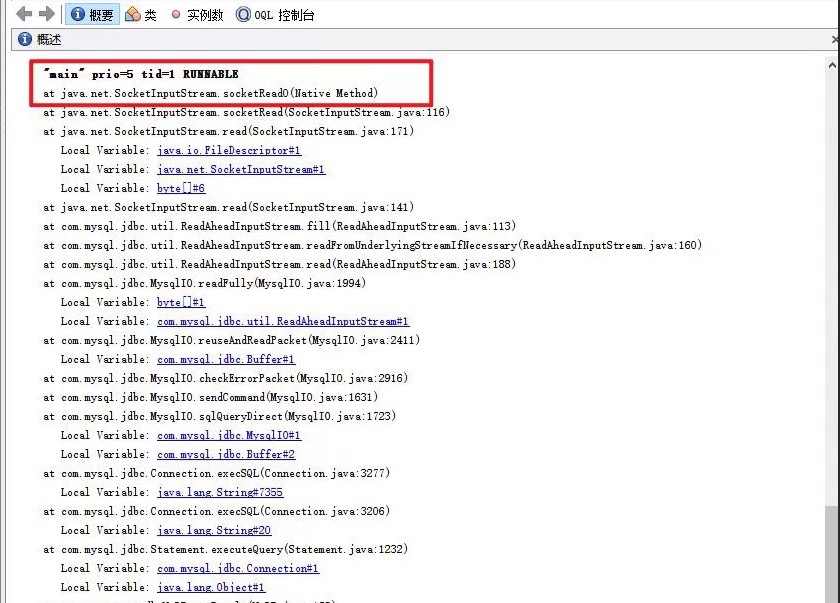
从堆栈可以看出来是阻塞在一条sql的执行过程中,并且是调用native方法时的socket阻塞,网上找到一篇类似的博文,推断可能是由于网络原因连接后没有响应造成 java.net.SocketInputStream.socketRead0一直阻塞等待读取。代码就不在这儿贴出来了,综合分析:代码实际运行是一个同步阻塞线程,程序从main方法进入开始调用,在进行sql查询时阻塞在java.net.SocketInputStream.socketRead0(Native Method)
知道是阻塞在哪里了,但是还有一个问题是为什么每次阻塞时间都是两小时,两小时一过就自动恢复了?z直到看到服务器上这么一条配置:
net.ipv4.tcp_keepalive_time = 7200这个配置行涉及到 Linux 内核参数
net.ipv4.tcp_keepalive_time,它决定了 TCP 栈在连接变得空闲后等待多长时间(以秒为单位)才发送第一个保持活动探测。在这个情况下,
net.ipv4.tcp_keepalive_time = 7200表示 TCP 保持活动时间被设置为 7200 秒,即 2 小时。在连接变得空闲并保持这个时间后,TCP 栈会开始发送保持活动探测来检查连接是否仍然活动。调整这个参数在想要更快地检测空闲连接或陈旧连接的情况下很有用,从而释放资源
我的理解是针对这次发生的socket阻塞,理论是会引起永久阻塞的,但由于系统内核设置7200s,所以在两小时后会自动断开,从而服务恢复正常;但是我没有直接的证据能够证明两小时后自动断开跟这个配置项有必然的联系,知识储备尚浅,一些底层的原理还不太清楚,要是有大佬来能够解惑那可就太棒了。
解决方案:
增加socket超时时间
mariadb-java-client [官方文档]写明可以在 JDBC URL 中指定网络IO 的超时参数:

优化数据库连接
另外还有一个问题就是,代码实现的方式比较古老,获取数据库连接还是原始的手动注册驱动,再获取连接,每一次任务都要重新获取一次连接,索性直接改了Hikari连接池。OK,至此完结。
